SpleeterGui V2.9.1 汉化最新版
- 软件介绍
- 人气下载
- 下载地址
- 网友评论
SpleeterGui是一款专业的AI智能音轨分离软件,基于TensorFlow开发,能够将歌曲拆分成单独的部分,只要配合Deezer发布的AI训练模型,就可以实现相当高质量的人声与伴奏分离。且软件对新手非常友好,基本满足用户的使用需求。
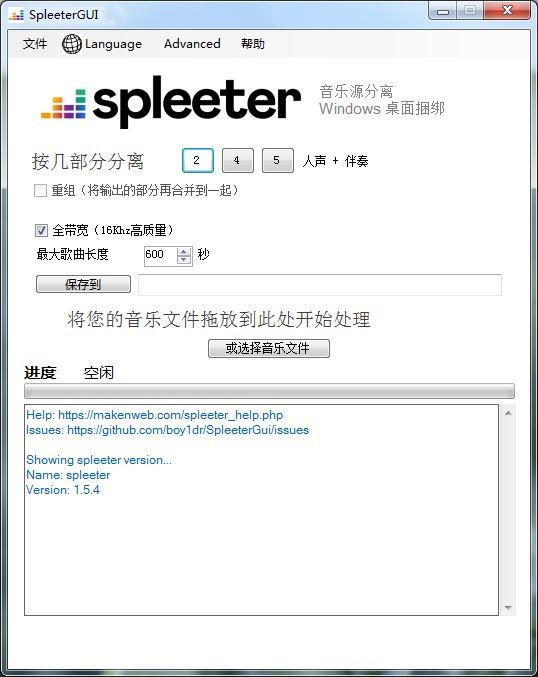
软件介绍
经常玩音乐的人,一定会用到伴奏和人声分离,比如Audition或者RX7,但是面对复杂的乐器分离,这两款软件就束手无策了。
Spleeter是由法国的音乐流媒体公司Deezer开源,需向Spleeter提供一个音频文件,它就会将其分成两个、四个、五个等多个独立的音轨,它支持mp3、wav、ogg等常见音频格式。一在Github上线便获超高好评和浏览。
功能特色
Spleeter基于TensorFlow开发,本身运行速度非常快。分离过程可以在GPU或CPU上执行。在GPU上运行,如果它将音频文件分成四个音轨,可以比实时速度快100倍。安装Spleeter并不难,只需克隆存储库并选择用 Conda 环境安装即可开始分离音频文件。由于操作还是很复杂的,需要有一定的python基础,所以国外大神做了个可视化版本,特此搬运。(虽然还是需要很多环境,但是总比python敲代码要简单太多了)
用户可以根据自己的需求来训练模型,Deezer 还给出了在 musdb 数据集上的预训练模型,因此能直接拿来使用。
在官方提供的预训练模型里,spleeter 可将人声和乐器声分为 2 个音轨,已经能满足基本的要求。此外它还能把乐器声进一步分离为鼓、贝斯、钢琴及其他乐曲,加上人声,spleeter 最多可以分离出 5 个音轨。
使用方式
1、一定先安装python环境(3.7.X 或者3.6.X版本)并添加path到系统环境变量。
2、直接解压并管理员身份运行SpleetGUI.exe(第一次启动的时候会慢,要在后台安装ffmpeg环境)。注意左下角的“spleeter”字样要有绿色背景,这样就说明环境安装是成功的,否则软件不能正确运行。右侧的文字也会有Requirement already satisfied的提示。
更新日志
将项目升级到64位。
人气下载






下载地址
- PC版
高速下载器通道:
其他下载地址:
本类总下载排名
- 1次 1 驿稻芸配音 V1.0.0 官方安装版
- 0次 2 DTS音效大师 V21.14 免费版
- 6次 3 Hydrogen(音频处理软件) V1.1.1 官方版
- 5次 4 一键录音 V1.7.8 官方最新版
- 0次 5 金舟音频人声分离软件 V2.2.0.0 官方最新版
- 30次 6 配音鹅 V1.0.0 官方安装版
- 30次 7 布谷鸟配音 V2.3.0 官方版
- 82次 8 Voice.AI(变声软件)V1.0 官方安装版
- 59次 9 Soft4Boost Any Audio Grabber(cd音乐提取软件) V9.0.7.975 官方版
- 46次 10 福昕音频剪辑 V1.0.2925.36 官方版
本类月下载排名
- 1次 1 驿稻芸配音 V1.0.0 官方安装版
- 0次 2 DTS音效大师 V21.14 免费版
- 6次 3 Hydrogen(音频处理软件) V1.1.1 官方版
- 5次 4 一键录音 V1.7.8 官方最新版
- 0次 5 金舟音频人声分离软件 V2.2.0.0 官方最新版
- 30次 6 配音鹅 V1.0.0 官方安装版
- 30次 7 布谷鸟配音 V2.3.0 官方版
- 82次 8 Voice.AI(变声软件)V1.0 官方安装版
- 59次 9 Soft4Boost Any Audio Grabber(cd音乐提取软件) V9.0.7.975 官方版
- 46次 10 福昕音频剪辑 V1.0.2925.36 官方版











